A good network monitoring tool is one of the most import tools of an IT department. It watches over your network and servers and alerts you when something is wrong (or even better, about to go wrong). It helps you to keep one step ahead of the problems.
I have been using a network monitoring tool for the past 10 years now, but recently the guys from NetCrunch reached out to me to check if I was interested in testing their new version, NetCrunch 10. As an IT guy, I always like to try out new tools and this is a good opportunity to compare it with my current monitoring tool, PRTG and write a NetCrunch Review.
So in this review, I am going to look at how easy it’s to set up NetCrunch. We are going to take a closer look at the interface of NetCrunch, the supported devices, remote probes, dashboard and of course the licensing model.
Installing NetCrunch
Installing NetCrunch is done in a couple of minutes. To get started you can download the NetCrunch Plaform Server trial. This will give you the full NetCrunch suite so you can fully test NetCrunch.
After you started the installation all you need to enter is the required port number. By default, the NetCrunch web interface is accessible on port 80. But during the installation, you can change this.
After the installation is done NetCrunch will help you with the network discovery. You can add every node by hand, but more convenient is to use the auto-discovery feature.
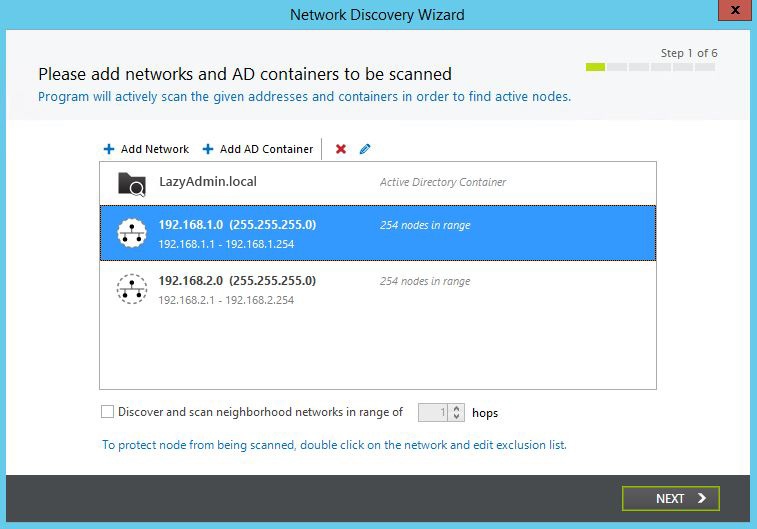
You will need to go through a couple of steps to scan your network. We can define which IP ranges we want to scan, add AD Container(s) and even discover neighboring networks.
The neighboring networks is actually a nice feature. It will find the network nodes from your ISP, for example, so you can easily monitor if you have internet-connection.
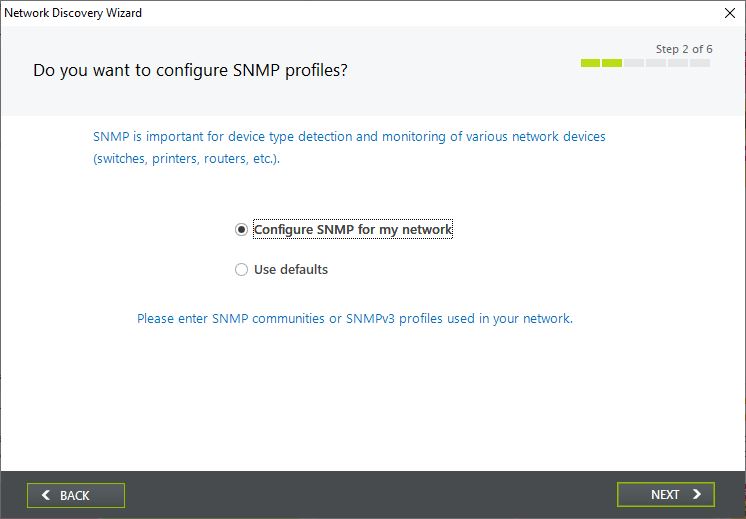
If you are using custom SNMP credentials for your network device, then make sure you select Configure SNMP for my Network in step 2. This allows you to enter your SNMP profiles in the next step. This way NetCrunch can read-out all your network devices.

One of the next steps is to select what you want to discover. NetCrunch can do a full network discovery, but then it will also list all the workstations and other clients in your network. If you don’t want this you can simply choose to do only an infrastructure scan. This will list all your routers, switches and servers.
After you started the network discovery NetCrunch will create a Network Atlas. The network scan only takes a couple of minutes (of course it depends on the number of devices you have)
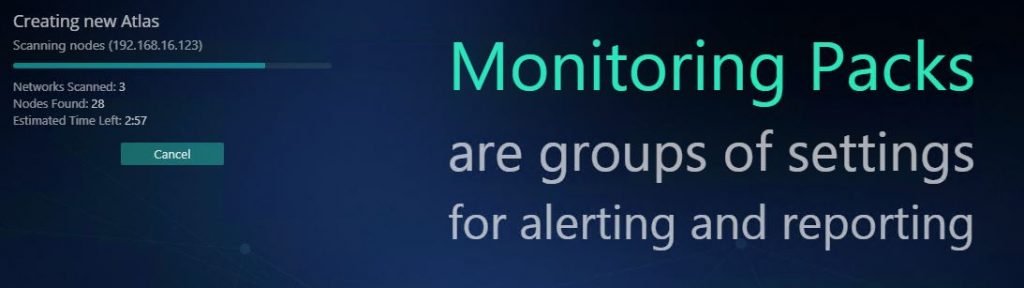
When the network discovery is completed, the last thing to do is to setup NetCrunch itself. You will need to enter the credentials of your network. Think of your SNMP accounts (if you didn’t add them in step 2), Windows Service account, Linux credentials, etc.
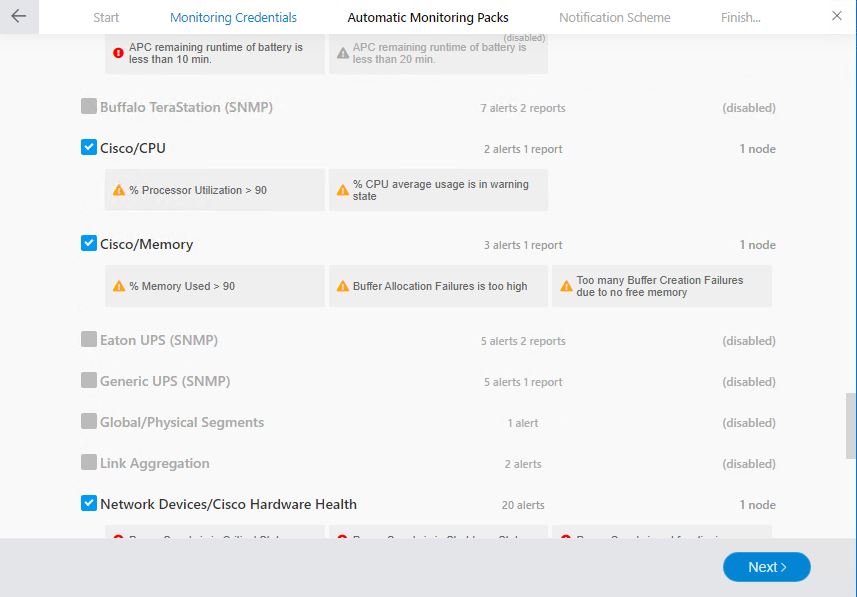
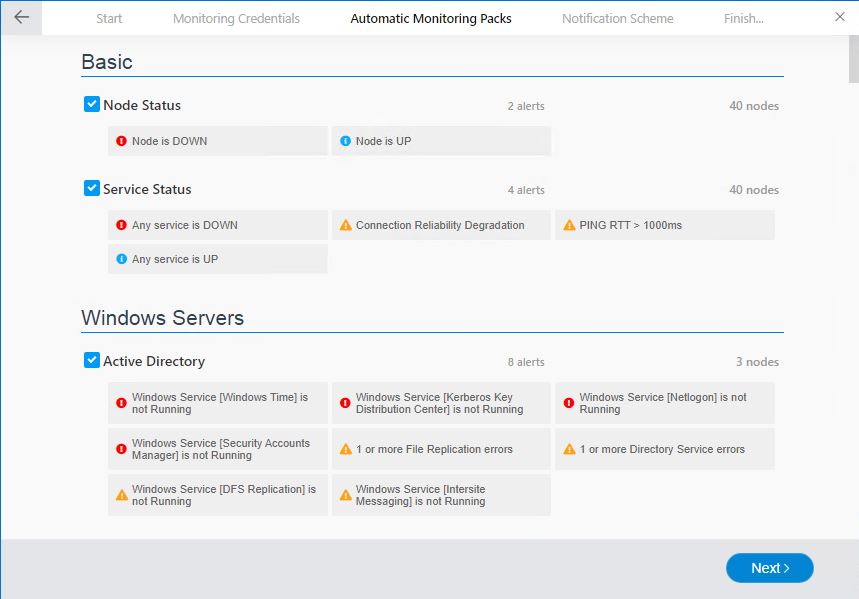
Also, you can choose what you want to monitor. During the network discovery, we defined which devices we want to monitor, but during this last step, you can select which monitoring packs you want to use.
For example, the USP runtime, you might want to get an alert if the runtime is less then 10 min, but don’t want an alert when it’s below 20min.
Most important information in one click
When you are monitoring your network it’s important to get a good overview of your network. With one look on the screen, you want to know if everything is ok or where the problem is.
When you open NetCrunch you will see the Network Atlas, one global overview of your network. Based on different metrics, like Monitoring Packs, services, sensors etc, it shows you the status of your network.
Now I am used to PRTG, and there you got a device tree as a dashboard with each device and every sensor on it that you want to monitor.
So at first, I needed to get used to this new layout. I was more comfortable with a list of all devices and each monitored component under it. The downside of the device three in PRTG is that it can get really long, so you will have to scroll or collapse groups.
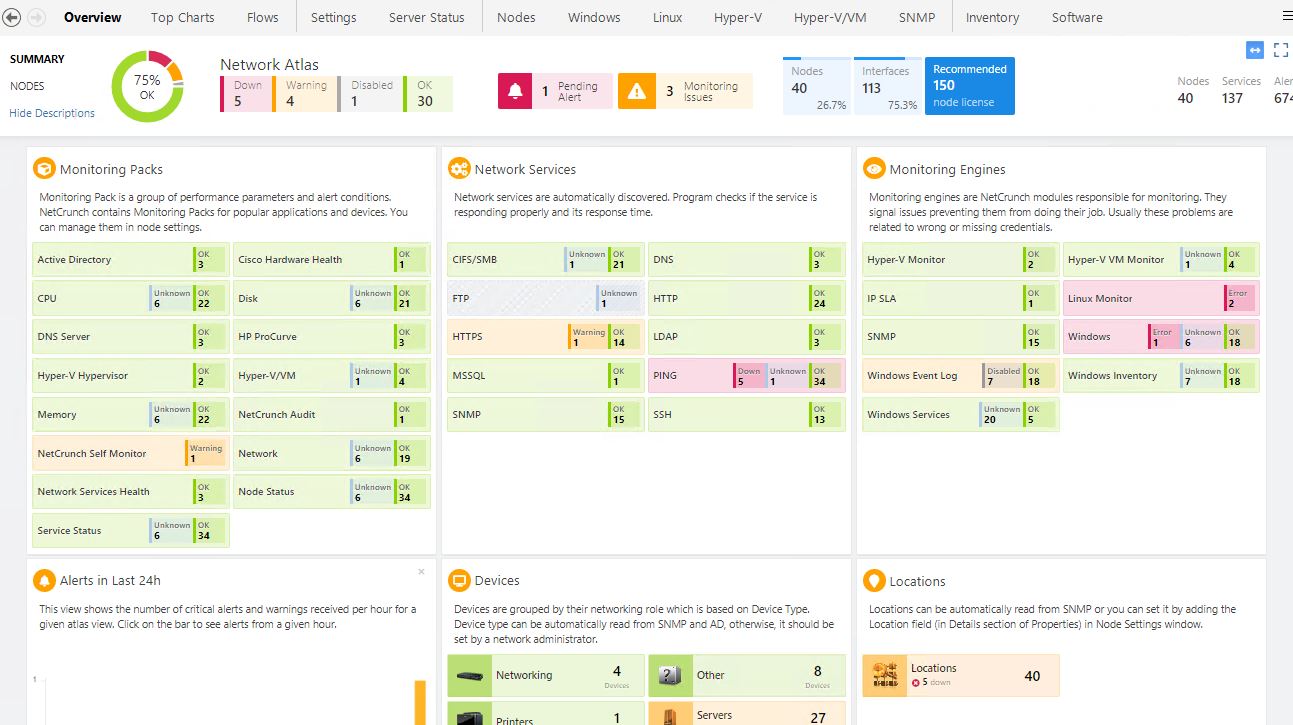
The Network Atlas, on the other hand, gives you a great overview of all the important components of your network. Is your Active Directory ok, are all the DNS servers up and running? If you are used to PRTG it’s a different way of looking at your network, but I like it.
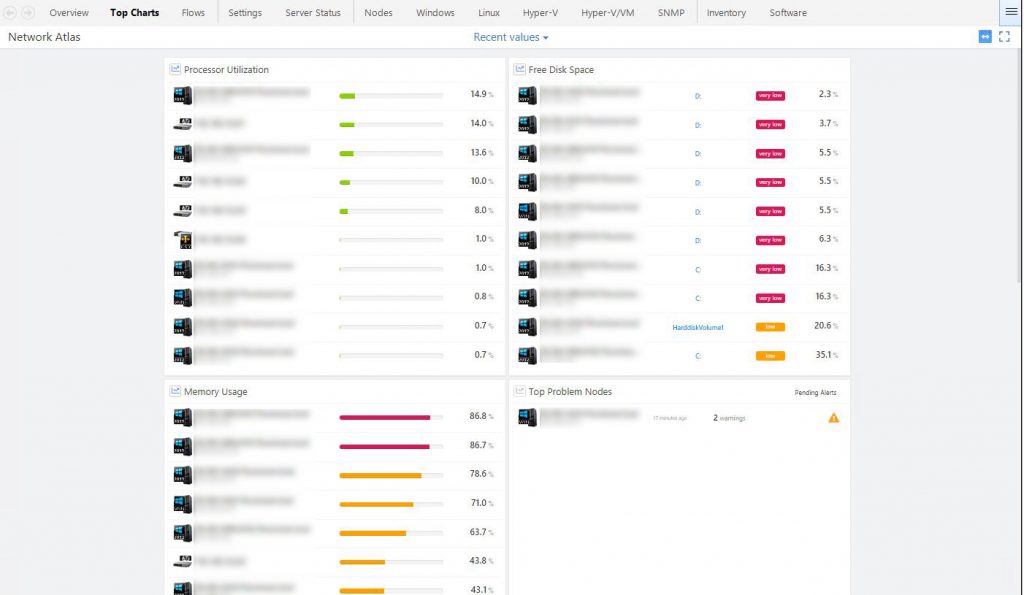
Top Charts
In NetCrunch they have done a great job with creating some powerful default views. For example the Top Charts, a view you probably will use a lot. Want to know which servers are running low on disk space? In the Top Charts, there is a nice list with the 10 servers that have the least free space.
Or what about high memory usage, high CPU utilization or slow responding nodes. No need to create reports for this. All information is available with one click.
Now seeing the alerts in a clear overview is nice, but you don’t want to look to the screen all the time. NetCrunch comes with some good options to get you, or your colleagues notified.
You can create different automatic notification based on different metrics, like time, device type, location or severity. These notifications can be sent by the traditional way, email or SMS, but also to your helpdesk system, or Microsoft Teams channel. NetCrunch integrates really nice with a lot of different applications.
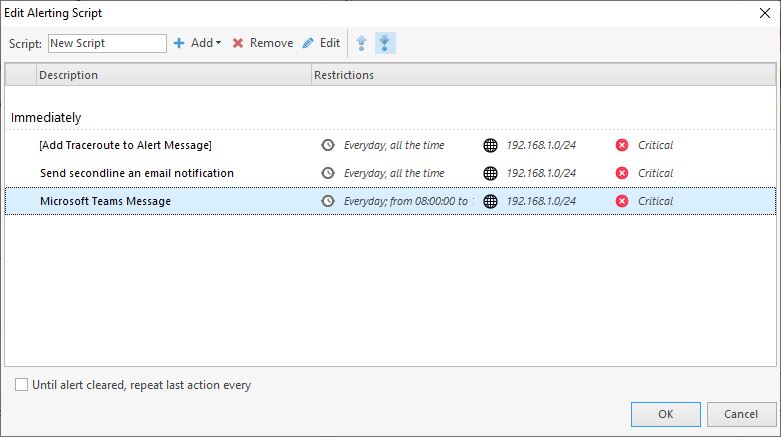
And sending a notification is not the only option, sometimes a simple reboot can solve the problem. So why don’t you let NetCrunch taking care of it? Just like notifications, you can create reboot scripts based on different conditions.
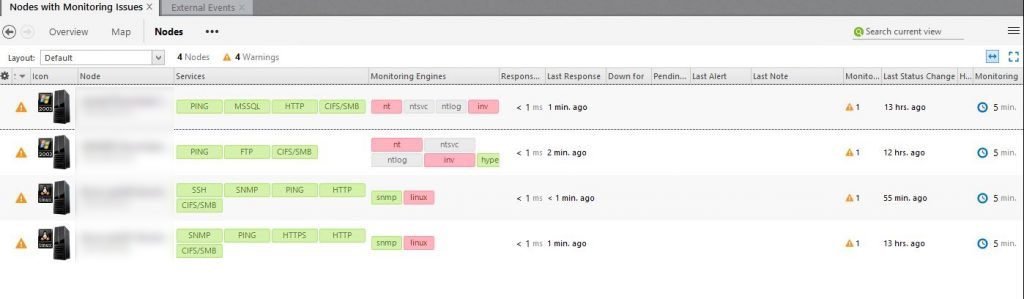
Nodes with a problem
From every place in NetCrunch, you can drill down a node to see that status or issues. It doesn’t matter if you are in the Network Atlas, a Top Chart or a network map. With one click on a node, you can select view status or it alerts.
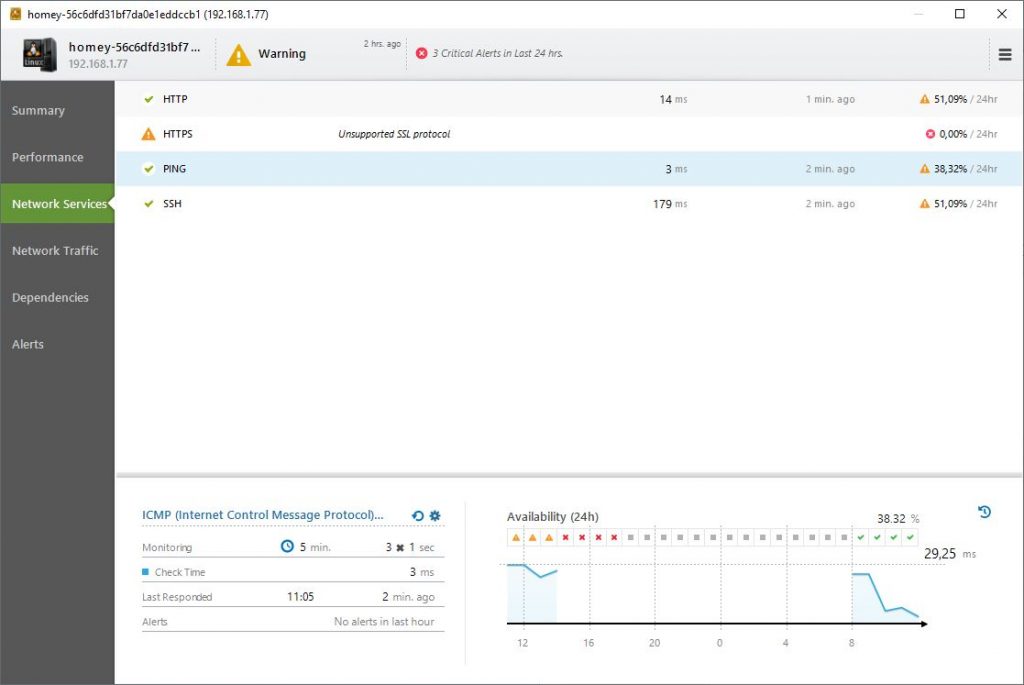

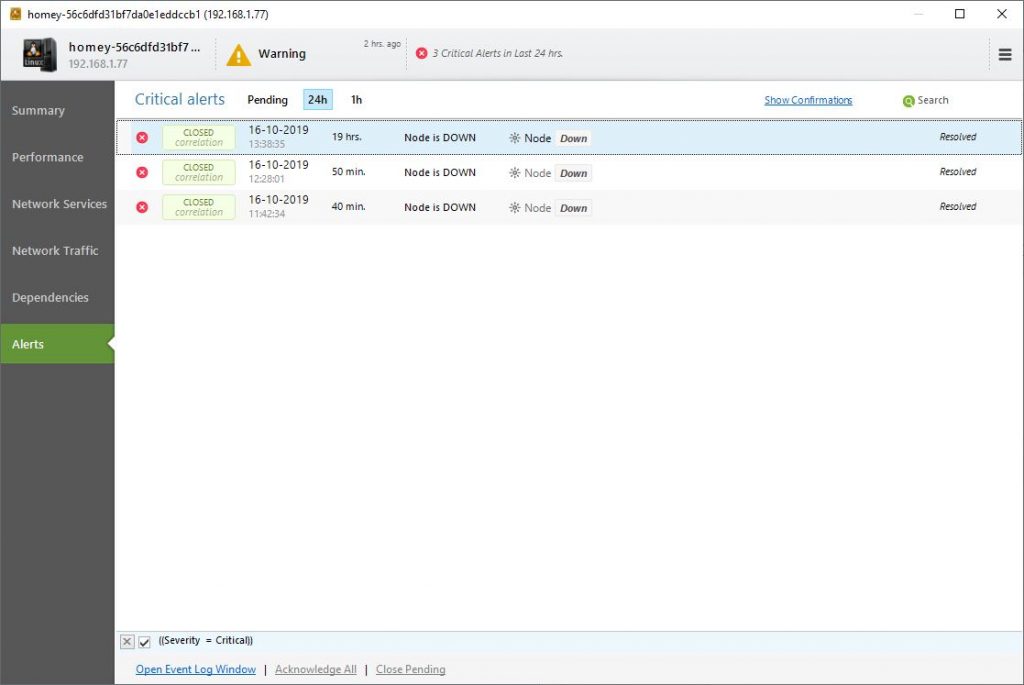
In the node view, you can complete drill down through the performance, services, and alerts. Completed with history and small graphs of the data. So basically all important information can be reached in only two or three clicks, which is great.
For a more general overview, you can use one of the custom views that you will find on the left side. Here you can select all nodes with an issue or alert, giving you a nice list of devices and their alerts.
Monitoring Packs
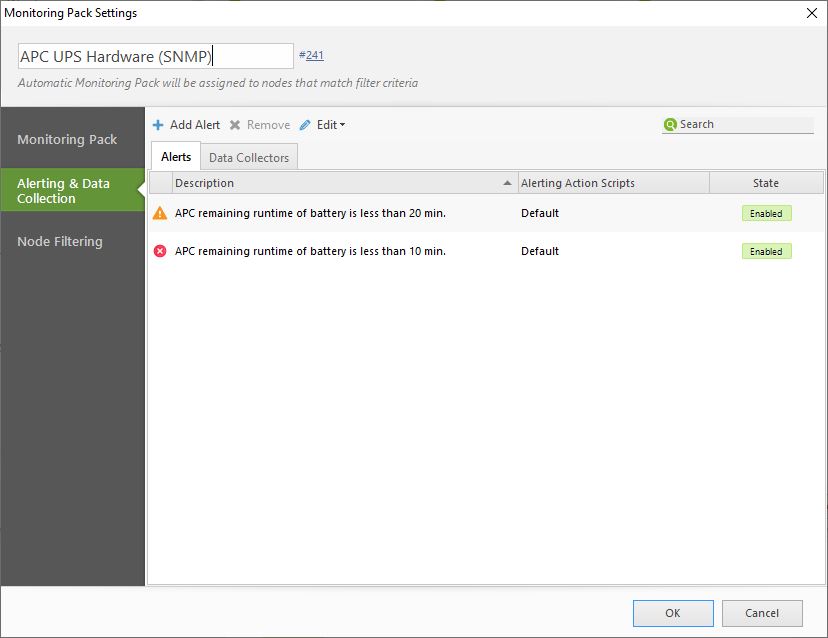
During the set up we already came across the monitoring packs, but what are they? Monitoring packs can best be described as a set of rules which describe which data to collect and what the thresholds are.
For example, we want to monitor our UPS. In the monitoring pack, we define when we want to receive an alert. So for a battery, if the runtime is below 10 minutes, we want a critical alert. If it’s below 20 minutes, a warning is sufficient.
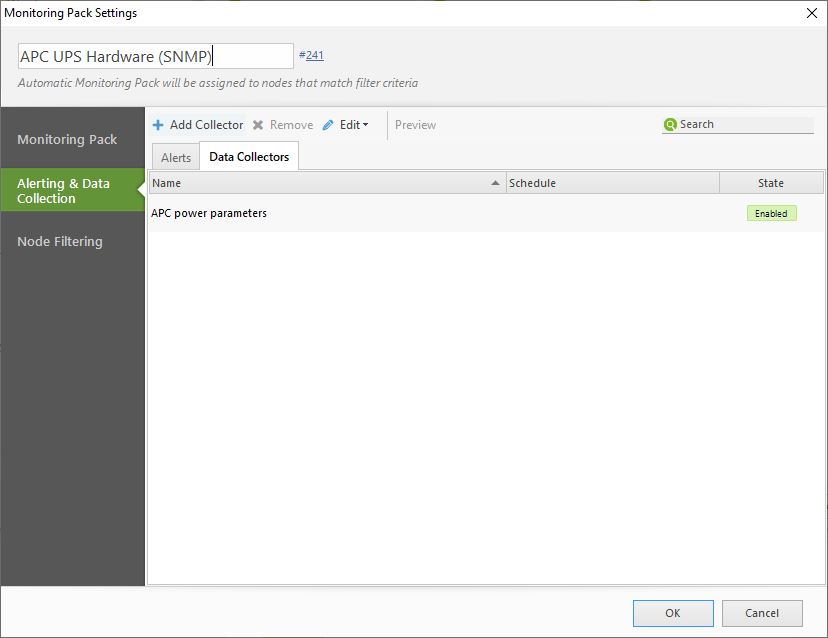
In the Data Collector tab, we can define which data we want to collect. For a battery, we want to collect the power parameters (capacity, battery status, temp, etc).
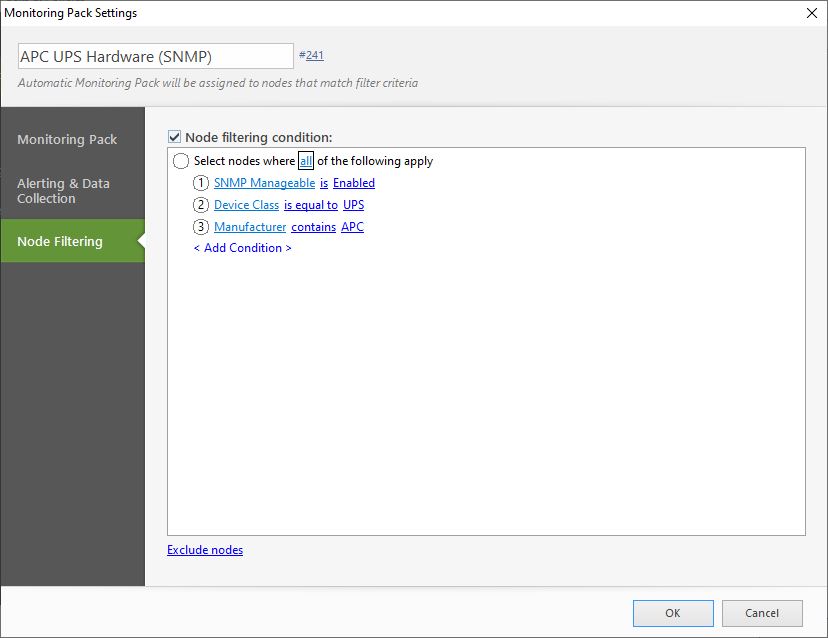
The last step is to define which nodes we want to apply the monitoring pack. Based on a couple of rules we can automatically apply the monitoring pack on every APC battery.
Now you don’t need to define the monitoring packs yourself, NetCrunch comes with more than 190 monitoring packs pre-installed. So there is a monitoring pack for the most common nodes available. But if that isn’t sufficient, then you can easily create your own.
Remote Probes
If your network exists of multiple sites you might want to use a remote probe. The master server maybe can’t reach all devices from your local network or you may want to split the load between multiple servers. Just like with PRTG you can use a remote probe for this.
You simply install the remote probe on a server in the network you want to monitor. All you need to do is make sure that the master server can reach the remote probe. The probe will collect local data and send it to the master server.
The only downside of the remote probe from NetCrunch is, is that it will stop monitor when the connection to the master server is lost. It won’t store the data locally and re-send it when the connection is restored. Something the remote probe from PRTG can do. It’s not a big deal, but when a connection is lost you might have a cap in your historic data.
Network Maps and Dashboards
While every monitoring tool can send an alert when something goes down, we all like to quickly check the status of our network. I have a 50″ TV hanging on the wall, so I can occasionally peak at the screen to see the most important metrics and get a feeling if everything is running fine.
Now the network atlas looks great, but may not be suitable for running on a monitoring screen. Just like PRTG, NetCrunch comes with a network map tool. This allows you to great your own network maps or dashboard.
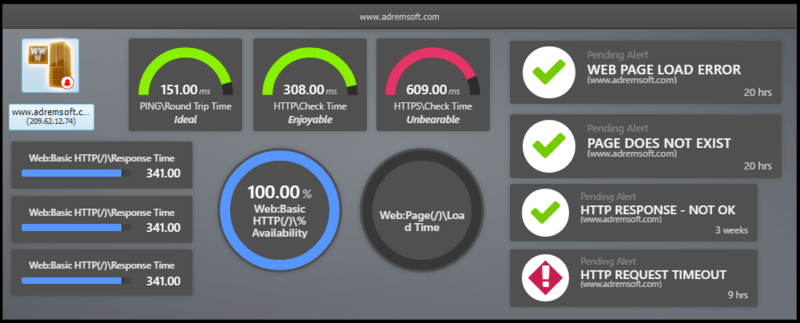
The network map from NetCrunch isn’t that extensive as that from PRTG, but one advantage is that you can use a dark background with the sensors on it.
GrafCrunch
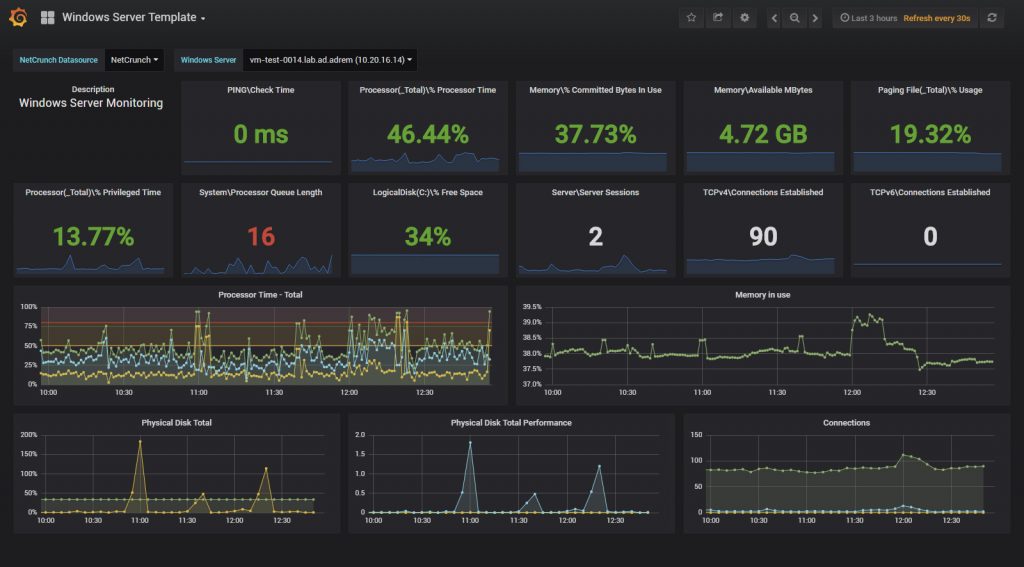
What I really like is that NetCrunch comes with its own fork of Grafana, named CraftCrunch. With CraftCrunch you can create a stunning dashboard that looks really nice and is perfect for monitoring screens. You can download and install GrafCrunch Dashboard Server on the same or separate server.
After you opened CraftCrunch you can add NetCrunch as a data source to it (make sure you download GraftCrunch and not Grafana self!). To get you started quickly it comes with prefined templates so you can set up some nice screen in a couple of clicks.
Conclusion
NetCrunch is a powerful monitoring tool that out of the box does a great job of monitoring your network. The initial setup is really simple and with the auto-discovery, it will find pretty much every important detail of your network.
Just like with PRTG you can fully customize every bit of your monitoring solution. You can create custom sensors or monitoring packs for your specific needs.
The interface looks great, I love the overview of the Network Atlas. The concept of monitoring packs and creating/customizing them took some time to understand, but they can really save you a lot of time in the end.